Log4j 2: Performance close to insane
Recently a respected member of the Apache community tried Log4j 2 and wrote on Twitter
@TheASF #log4j2 rocks big times! Performance is close to insane ^^ http://logging.apache.org/log4j/2.x/
It happened shortly after Remko Popma contributed something which is now called the “AsyncLoggers”. Some of you might know Log4j 2 has AsyncAppenders already. They are similar like the ones you can find in Log4j 1 and other logging frameworks.
I am honest: I wasn’t so excited about the new feature until I read the tweet on its performance and became curious. Clearly Java logging has many goals. Among them: logging must be as fast as hell. Nobody wants his logging framework to become a bottleneck. Of course you’ll always have a cost when logging. There is some operation the CPU must perform. Something is happening, even when you decide NOT to write a log statement. Logging is expected to be invisible.
Until now, the well-known logging frameworks were similar in speed. Benchmarks are unreliable after all. We have made some benchmarks over at Apache Logging. Sometimes one logging frameworks wins, sometimes the other. But at the end of the day you can say they are all very good and you can choose whatever your liking is. Until we got Remko’s contribution and Log4j 2 became “insanely fast”.
Small software projects running one thread might not care about performance so much. When running a SaaS you simply don’t know when your app gets so much attraction that you need to scale. Then you suddenly need some extra power.
With Log4j 2, running 64 threads might bring you twelve times more logging throughput than with comparable frameworks.
We speak of more than 18,000,000 messages per second, while others do around 1,500,000 or less in the same environment.
I saw the chart, but simply couldn’t believe it. There must be something wrong. I rechecked. I ran the tests myself. It’s like that: Log4j 2 is insanely fast.
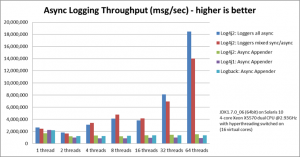
Async Performance, last read on July 19, 2013
As of now, we have a logging framework which performs lots better than every other logging framework out there. As of now we need to justify our decision when we do not want to use Log4j 2, if speed matters. Everything else than Log4j 2 can become a bottleneck and a risk. With such a fast logging framework you might even consider to log a bit more in production than you did before.
Eventually I wrote Remko an e-mail and asked him what exactly the difference between the old AsyncAppenders and the new Asynchronous Loggers is.
The difference between old AsynAppenders and new AsyncLoggers
“The Asynchronous Loggers do two things differently than the AsyncAppender”, he told me, “they try to do the minimum amount of work before handing off the log message to another thread, and they use a different mechanism to pass information between the producer and consumer threads. AsyncAppender uses an ArrayBlockingQueue to hand off the messages to the thread that writes to disk, and Asynchronous Loggers use the LMAX Disruptor library. Especially the Disruptor has made a large performance difference.”
In other terms, the AsyncAppender use a first-in-first-out Queue to work through messages. But the Async Logger uses something new - the Disruptor. To be honest, I had never heard of it. And furthermore, I never thought much about scaling my logging framework. When somebody said “scale the system”, I thought about the database, the app server and much more, but usually not logging. In production, logging was off. End of story.
But Remko thinks about scaling when it comes to logging.
“Looking at the performance test results for the Asynchronous Loggers, the first thing you notice is that some ways of logging scale much better than others. By scaling better I mean that you get more throughput when you add more threads. If your throughput increases a constant amount with every thread you add, you have linear scalability. This is very desirable but can be difficult to achieve.”, he wrote me.
“Comparing synchronous to asynchronous, you would expect any asynchronous mechanism to scale much better than synchronous logging because you don’t do the I/O in the producing thread any more, and we all know that ‘I/O is slow’ (and I’ll get back to this in a bit)”.
Yes, exactly my understanding. I thought it would be enough to send something to a queue, and something else would pick it up and write the message. The app would go on. This is exactly what the old AsyncAppender does, wrote Remko:
“With AsyncAppender, all your application thread needs to do is create a LogEvent object and put it on the ArrayBlockingQueue; the consuming thread will then take these events off the queue and do all the time-consuming work. That is, the work of turning the event into bytes and writing these bytes to the I/O device. Since the application threads do not need to do the I/O, you would expect this to scale better, meaning adding threads will allow you to log more events.”
If you believed that like me, take a seat and a deep breath. We were wrong.
“What may surprise you is that this is not the case.”, he wrote.
“If you look at the performance numbers for the AsyncAppenders of all logging frameworks, you’ll see that every time you double the number of threads, your throughput per thread roughly halves.”
“So your total throughput remains more or less flat! AsyncAppenders are faster than synchronous logging, but they are similar in the sense that neither of them gives you more total throughput when you add more threads.”, he told me.
It hit me like a hammer. Basically instead of making your logging faster with adding more threads you made basically: nothing. After all Appenders didn’t scale until now. I asked Remko why this was the case.
“It turns out that queues are not the most optimal data structure to pass information between threads. The concurrent queues that are part of the standard Java libraries use locks to make sure that values don’t get corrupted and to ensure data visibility between threads.”.
LMAX Disruptor?
“The LMAX team did a lot of research on this and found that these queues have a lot of lock contention. An interesting thing they found is that queues are always either full or empty: If your producer is faster, your queue will be full most of the time (and that may be a problem in itself :-) ). If your consumer is fast enough, your queue will be empty most of the time. Either way, you will have contention on the head or on the tail of the queue, where both the producer and the consumer thread want to update the same field. To resolve this, the LMAX team came up with the Disruptor library, which is a lock-free data structure for passing messages between threads. Here is a performance comparison between the Disruptor and ArrayBlockingQueue: Performance Comparison.”
Wow. After all these years of Java programming I actually felt a bit like a Junior programmer again. I missed the LMAX disruptor and even never considered it a performance problem to use the Queue. I wonder what other performance problems I did not discover so far. I realized, I had to re-learn Java.
I asked Remko how he could find a library like the LMAX disruptor. I mean nobody writes software, creates an instance of a Queue-class, doubts its performance and finally searches the internet for “something better”.
Or are there really people of that kind?
“How I found about the Disruptor? The short answer is, it was all a mistake.”, he started.
“Okay, perhaps that was a bit too short, so here is the longer answer: a colleague of mine wrote a small logger, essentially adding a time-stamped log message to a queue, with a background thread that took these strings off the queue and wrote them to disk. He did this because he needed better performance than what he could get with log4j-1.x. I did some testing and found it was faster, I don’t remember exactly by how much. I was quite surprised because I had been using log4j for years and had never thought it would be easily outperformed. Until then I had assumed that the well-known libraries would be fast, because, well… To be honest, I had just assumed. So this was a bit of an eye-opener for me. However, the custom logger was a bit bare-bones in terms of functionality so I started to look around for alternatives.”
“Before I start talking about the Disruptor, I have to confess something. I recently went back to see how much faster the custom logger was than log4j-1.x, but when I measured it it was actually slower! It turned out that I had been comparing the custom logger to an old beta of log4j-2.0, I think beta3 or beta4. AsyncAppender in those betas still had a performance issue (LOG4J2-153 if you’re curious). If I had compared the custom logger to the AsyncAppender in log4j-1.x, I would have found that log4j-1.x was faster and I would not have thought about it further. But because I made this mistake I started to look for other high-performance logging libraries that were richer in functionality. I did not find such a logging library, but I ran into a whole bunch of other interesting stuff, including the Disruptor. Eventually I decided to try to combine Log4j-2, which has a very nice code base, with the Disruptor. The result of this was eventually accepted into Log4j-2 itself, and the rest, as they say, was history.”
“One thing I came across that I should mention here is Peter Lawrey’s Chronicle library. Chronicle uses memory-mapped files to write tens of millions of messages per second to disk with very low latency. Remember that above I said that “we all know that I/O is slow”? Chronicle shows that synchronous I/O can be very, very fast.”.
“It was via Peter’s work that I came across the Disruptor. There is a lot of good material out there about the Disruptor. Just to give you a few pointers:
- Martin Fowler: LMAX
- Trisha Gee on LMAX under the hood (slightly outdated now but the most detailed material I know of)
- ...and video presentations like this
The Disruptor google group is also highly recommended.
Recommended readings on Java performance in general are:
Martin Thompson has done a number of articles and presentations on various aspects of high performance computing in java. He does a great job of making the complex stuff that is going on under the hood accessible.”
My bookmarks folder went full after reading this e-mail, and I appreciate the lots of starting points for improving my knowledge on Java performance.
Should I use AsyncLoggers by default?
I was sure I want to use the new Async Loggers. This all sounds just fantastic. But on the other hand, I am a bit scared and even a little paranoid to include new dependencies or new technologies like the new Log4j 2 Async Loggers. I asked Remko if he would use the new feature by default or if he would enable them just for a few, limited use cases.
“I use Async Loggers by default, yes.”, he wrote me. “One use case when you would not want to use asynchronous logging is when you use logging for audit purposes. In that case a logging error is a problem that your application needs to know about and deal with. I believe that most applications are different, in that they don’t care too much about logging errors. Most applications don’t want to stop if a logging exception occurs, in fact, they don’t even want to know about it. By default, appenders in Log4j-2.0 will suppress exceptions so the application doesn’t need to try/catch every log statement. If that is your usage, then you will not lose anything by using asynchronous loggers, so you get only the benefits, which is improved performance.”
“One nice little detail I should mention is that both Async Loggers and Async Appenders fix something that has always bothered me in Log4j-1.x, which is that they will flush the buffer after logging the last event in the queue. With Log4j-1.x, if you used buffered I/O, you often could not see the last few log events, as they were still stuck in the memory buffer. Your only option was setting immediateFlush to true, which forces disk I/O on every single log event and has a performance impact. With Async Loggers and Appenders in Log4j-2.0 your log statements are all flushed to disk, so they are always visible, but this happens in a very efficient manner.”
Isn’t it risky to log to use Log4js AsyncLoggers?
But considering that Log4j-1 had serious threading issues and the modern world uses cloud computing and clustering all the time to scale their apps, isn’t asynchronous logging some kind of additional risk? Or is it safe? I knew my questions would sound like the questions of a decision maker, not of an developer. But the whole LMAX thing was so new to me and since I maintain the old and really ugly Log4j 1 code, I simply had to ask.
Remko: “There are a number of questions in there. First, is Log4j-2 safer from a concurrency perspective than Log4j-1.x? I believe so. The Log4j-2 team has put in considerable effort to support multi-threaded applications, and the asynchronous loggers are just a very recent and relatively small addition to the project. Log4j-2 uses more granular locking than log4j-1.x, and is architecturally simpler, which should result in fewer issues, and any issues that do come up will be easier to fix.”
“On the other hand, Log4j-2 is still in beta and is under active development, although recently I think most effort is being spent on fixing things and tying up loose ends rather than adding new features. I believe it is stable enough for production use. If you are considering using Log4j-2, for performance or other reasons, I’d suggest you do your due diligence and test, just like you would before adopting any other 3rd party library in your project.”
(Sidenote: A stable version of Log4j2 can be expected soon, most likely autumn 2013).
Sounded good to me. And yes, I can perfectly agree with that from my own observations on the project, though I personally did not write code in the Log4j 2 repository.
“The other question I see is: Is asynchronous logging riskier than synchronous logging? I don’t think so, in fact, if your application is multi threaded the opposite may be the case: once the log event has been handed off to the consumer thread that does the I/O, there is only that one thread dealing with the layouts, appenders and all the other logging-related components. So after the hand-off you’re single-threaded and you don’t need to worry about any threading issues like deadlock and liveliness etc any more.”
“You can take this one step further and make your business logic completely single-threaded, using the disruptor for all I/O or communication with external systems. Single-threaded business logic without lock contention can be blazingly fast. The results at LMAX (6 million transactions/sec, with less than 10 ms latency) speak for themselves.”
Reading Remko’s message I learned three things.
First, I had to learn more about Java performance. Second, I definitely want to make my applications use Log4j 2. As first step, I will enable it in my Struts 2 apps, which I use often. Third, a web application framework using the LMAX Disruptor might blow us all away.
I would like to give a big thank you and a hug to Remko Popma for answering my questions and working on this blog post with me. All errors are my own.
Remko Popma

Twenty years ago, Remko went to Japan to get better at the game of Go. Somehow he never made it back. Remko started doing software development for Japanese software companies, had a brief stint as a freelance developer, ran a software company together with a Japanese partner, and is now leading algorithmic trading development in Mizuho Securities IT. He lives in Tokyo with his wife Tomoe and son Tobias.
Tags: #Apache log4j #Java #Open Source